At Broadleaf Commerce, we’ve had a number of prospective clients recently ask us about our support for a geographically distributed, multi-master, “always on” architecture. Our clients told us that they need an architecture where at least two geographic regions or data centers concurrently serve traffic. If an entire geography or data center goes down, there will be little or no disruption to customers or users who will fail over to another active data center. This implies that all data changes must be propagated between data centers or regions. The most complicated part of architecture like this is the database that must have redundancy and provide ACID-compliant semantics across a distributed cluster. A busy eCommerce application needs to perform and scale well too!
We looked briefly at several good platforms, including BDR from EnterpriseDB, CockroachDB, Google Spanner, and YugabyteDB. Due to specific client recommendations and requests, our focus shifted to Google Spanner and YugabyteDB. While I think all of these database platforms could work for various reasons, we determined that YugabyteDB provides the full suite of features and performance characteristics that we were looking for to best support an always-on eCommerce deployment.
About Broadleaf Commerce
Broadleaf Commerce provides an eCommerce framework built in Java on The Spring Framework. Broadleaf’s latest flagship offering is a Microservices-oriented eCommerce framework including 26+ services. These services maintain strictly bounded contexts and have their own database (or DB schema, if supported by the database platform). They can be deployed using Docker and Kubernetes in multiple cloud environments or a private cloud or data center. They are decoupled, so you can generally pick and choose which services you want to incorporate into your ecosystem without being forced to adopt all of them. Each service was designed to provide the best-of-breed technology and architecture to expose requisite eCommerce data and functionality. And because it is a framework, Broadleaf Commerce provides libraries, tools, configurations, SDKs, scripts, and demo or reference implementations and was carefully designed to be extended, overridden, customized, integrated, and otherwise expanded upon to meet the unique, complex multi-tenant, multi-catalog requirements of many B2C, B2B, and Marketplace companies. Broadleaf services can be deployed (and scaled) individually, or they can be bundled together in various ways to make more efficient use of hardware (more on this later).
As I mentioned, Broadleaf Commerce is built on top of The Spring Framework, including Spring Boot, Spring Data, Spring Cloud Stream, JPA (Hibernate), and other best-of-breed technologies like Apache Solr, React.js, Docker, and Kubernetes.
Additionally, Broadleaf Commerce supports multiple RDBMS platforms, including PostgreSQL (default), MySQL, MariaDB, Oracle, and, most recently, YugabyteDB.
Finally, our clients can deploy and manage Broadleaf Commerce in various Cloud environments or private Clouds, or data centers. Or our clients can employ us to host their solution in our fully-managed PaaS environment.
About Yugabyte
Yugabyte is the company behind YugabyteDB, the open-source distributed SQL database for scalable, cloud-native applications. YugabyteDB eliminates legacy database tradeoffs by combining the best of SQL—consistency, familiar interfaces, and security—with the best of NoSQL—resilience, horizontal scalability, and geo-distribution—into a single logical database built for transactional applications. YugabyteDB helps developers and IT teams focus on innovation instead of complex data infrastructure management. Fortune 500 companies like Kroger, Wells Fargo, and GM deployed YugabyteDB to modernize their data layer, reduce dependencies on legacy solutions, and enable an always-on business free from cloud lock-in.
Our Evaluation
We were tasked with evaluating or proving whether Broadleaf Commerce could operate efficiently and effectively with a distributed database in a geographically distributed, multi-master deployment environment. We were focused on compatibility, reliability/redundancy, and performance.
Due to time constraints and client preference, we focused our efforts on YugabyteDB and Google Spanner. In particular, we were looking for the following (or similarly comparable) features:
- Support for PostgreSQL Wire Protocol (or JDBC Driver and Hibernate Dialect)
- Support for Common Table Expressions (CTE) for recursive queries
- Support for multiple schemas within the same DB (not required but nice to have)
- Distributed ACID-compliant Transactions
- Distributed, redundant database allowing for node failure
- A platform that can survive a full region outage with little or no data loss
- Lowest possible latency (i.e., reasonable performance for a busy eCommerce site)
- Cloud or service-based offering
Our methodology was relatively simple: Get the full application stack working in Google Cloud (GCP) against YugabyteDB and Google Spanner and subjectively evaluate responsiveness. This included the following basic activities:
- Adjust DDL and DML scripts to compensate for differences between existing scripts and the database platforms that we were evaluating
- Modify configurations including JDBC Driver, URL, DataSource configurations, etc.
- Deploy the databases and applications to GCP
- Ensure that the application started up, created schemas, tables, indexes, and seed data
- Address issues, fix bugs, etc.
- Click through and exercise the Admin Console and Customer-facing application and subjectively evaluate them for responsiveness and accuracy compared with native PostgreSQL and try to improve performance and latency
- Note that we did not do a complete load or stress tests or test performance under load
On the surface, YugabyteDB and Google Spanner are very similar. Yugabyte claims that Google Spanner inspires their product. Google Spanner is truly a Database-as-a-Service. Yugabyte, on the other hand, provided us with an evaluation license to use their management and deployment tools to install and configure the database clusters as needed in GCP. This was extremely helpful, and I would recommend these tools. This is being branded as “YugabyteDB Anywhere.” Yugabyte also offers “YugabyteDB Managed,” a hosted cloud solution that delivers a fully-managed YugabyteDB-as-a-Service. This was relatively new at the time of our evaluation and did not provide all of the features and topologies that we were interested in, so we couldn’t use the Cloud offering at that time. Both platforms met all of the requirements described above. However, Spanner lacked the following areas:
- Support for Common Table Expressions (CTE) for recursive queries
- Lowest possible latency (reasonable performance for an eCommerce site).
We were able to work around Spanner’s lack of support for CTEs by refactoring some queries. Both platforms initially performed quite similarly (with high levels of latency) as Broadleaf services simply interacted with them in a default way (as if they were monolithic, single-region databases).
Both Spanner and YugabyteDB support the concept of follower reads (a.k.a. stale reads), which can reduce latency and improve performance at the expense of reading stale data. We felt that this might be helpful, especially in some cases. Follower reads - for both platforms - required that we intercept the JDBC connection, set the transaction to read only and supply a hint to the query or prepared statement. Follower reads probably work great for customer interactions like reading catalog data or other data types that are mostly read-only from the customer’s perspective. However, for admin users, we felt that it was important to query the latest, most accurate data since administrators need an accurate view of the data, and that data may be changed via the administrative console. With default (non-stale) reads, the latency in many cases was just too long because of the geographic distance between nodes. This led to the application being slow and sluggish. Additionally, for many operations within Broadleaf Commerce, there are writes followed fast by reads (e.g., OAuth flows in Authentication Services). In these cases, strong reads have unacceptable latency. Unfortunately, stale reads result in unexpected or unwanted application behavior. Choosing between poor performance and lost data or unpredictable application behavior is exactly what we were trying to avoid.
We determined that with some work, we could re-engineer Broadleaf to handle stale reads better to make things more efficient without the unpredictable behavior. However, YugabyteDB offered some additional capabilities that were useful and required no additional changes to the default Broadleaf Commerce application behavior.
YugabyteDB Topologies to the Rescue
YugabyteDB provides four multi-region deployment topologies, two of which can specifically be used together to provide a reasonable and pragmatic solution that balances reliability with performance in a multi-master configuration:
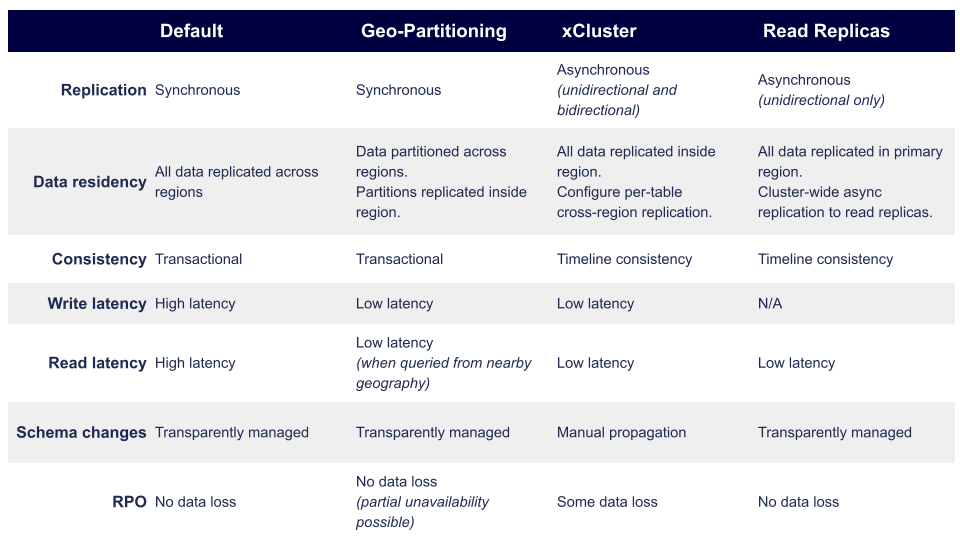
Source: https://docs.yugabyte.com/preview/explore/multi-region-deployments/
Note that the GEO-PARTITIONING and READ REPLICAS topologies are outside of the scope of this discussion. We’ll be focusing on the DEFAULT (a.k.a. SYNCHRONOUS) topology and the XCLUSTER topology with bidirectional asynchronous replication. These topologies can work together to store and serve different types of data with different levels of latency and consistency guarantees. And since each Broadleaf Commerce microservice can be assigned its own database (or database schema), we can assign each microservice to one of these topologies to achieve our goals.
DEFAULT Topology (synchronous and transactional across all regions)
YugabyteDB’s default (or synchronous) topology is a clustered database topology that can exist in a single region (e.g., across multiple availability zones) or across multiple geographic regions (e.g., US East, US Central, US West). This topology guarantees distributed, ACID-compliant transactions across all nodes as well as redundancy of data to mitigate the possibility of a node failure. If these nodes are distributed across geographic regions, then these guarantees extend across regions as well. This topology provides what we traditionally expect from an RDBMS system in that it provides ACID-compliant transactions across a cluster as if it were one monolithic database. This means that reads and writes have the same transactional guarantees as you would expect from a monolithic DB. The only problem is that distributed transactional systems like this whose member nodes span large geographical areas, can suffer from high latency levels due to long-distance network hops and distributed node coordination and consensus. This topology provides the best guarantees of durability and consistency, but at the expense of latency.
It’s fair to say that the synchronous default topology is most similar to Google Spanner in design, features, and performance. It’s also fair to say that this topology provides the best transactional guarantees and that latency and resulting performance problems are the biggest challenges that can manifest from using this topology.
This default synchronous topology is also the foundation or basis for each of the two XCLUSTER topologies that we’ll discuss later.
One note about these clusters is that they require a minimum of 3 nodes to have any failover or redundancy. Yugabyte recommends odd numbers of servers because odd numbers are required for leader elections and consensus. So with three nodes, you can survive one node failure. With five nodes, you can survive two node failures and so on. Additional nodes, though, allow for additional DB load balancing.
XCLUSTER Topology (synchronous and transactional within one region, with asynchronous, bidirectional replication across all regions)
The XCLUSTER topologies are interesting because they are essentially two identical DEFAULT (or synchronous) clusters operating as if they are one, each in a separate region or data center with asynchronous, bi-directional replication turned on between them. For example, you might have an XCLUSTER deployed in the US East Region (e.g. North Carolina) and an identical cluster in the US West Region (e.g. Oregon).
As noted, previously, XCLUSTER topologies are the same as a default, synchronous topology. In other words, each cluster (East or West coast, for example) is fully ACID-compliant across multiple DB nodes in that region. What makes them unique is that once a transaction is committed, they asynchronously replicate changes to each other, bidirectionally.
The result of this type of topology is that latency is vastly reduced (because all synchronous reads and writes are in a single, regional data center, which reduces latency and defers geographically distant replication to an asynchronous process). The risk with this topology is that a transaction is possibly commited to one side of the XCLUSTER that is not replicated to the other side of the XCLUSTER. Hypothetically, this could happen after a write is committed and then when an outage occurs before replication happens. Again, within a single data center or region, the transactions are ACID-compliant so you won’t likely lose data in that region. But because of the asynchronous nature of the replication, there are opportunities for the appearance of data loss, manifested as stale reads in case of a major regional outage. Data replication happens quickly, so losses are expected to be minimal. But they can still happen. And regional failure is expected to be rare. Still, one has to balance latency and performance with possible data loss or (more likely) extended stale reads (because data is usually not lost, but is delayed in replicating to the other region where the customer’s traffic is now routed). Needless to say, read-only (or read-mostly) operations from the customer’s perspective are good candidates for the XCLUSTER topology. Additionally, transient data such as OAuth tokens (authentication data) is a good candidate for XCLUSTER, especially because authentication performs multiple reads and writes which benefit from lower latency at the expense of a customer needing to log in again in the event of a regional outage during their session. That’s a relatively small price to pay for better performance.
The best way to mitigate data loss is to avoid using this topology for highly transactional customer interactions (e.g., inventory, completed orders, payment data, customer data, and cart data). Again, the tradeoff is latency and performance.
Similar to the SYNCHRONOUS (default) topology, each XCLUSTER requires a minimum of 3 server nodes to survive a single node failure. Five nodes allow for two node failures and so on. While DEFAULT synchronous topologies have nodes across at least three regions, XCLUSTER topologies have nodes, typically across three availability zones within one region and with an identical XCLUSTER in another region.
Putting it all together
Given that we have two types of clusters or topologies, SYNCHRONOUS (default) and XCLUSTER, we need to organize our services so that they use the most appropriate topology for their type of data and for the expected customer interaction. In general, from a customer point of view, data that is read-mostly should be stored in XCLUSTER. Transactional customer data that must not be lost, even temporarily (e.g., inventory changes, submitted orders, and payment details) should be transactionally synchronized across regions.
Here is a list of Broadleaf Commerce services and our recommendations for their deployment topology on YugabyteDB:
|
Service |
DEFAULT
|
XCLUSTER (asynchronous replication)
|
|
Admin Metadata Service |
X |
|
|
Admin Navigation Service |
X |
|
|
Admin User Service |
X |
|
|
Asset Service |
X |
|
|
Authentication Service |
X |
|
|
Campaign Service |
X |
|
|
Cart Service |
X* |
X |
|
Catalog Service |
X |
|
|
Content Service |
X |
|
|
Customer Service |
X* |
X |
|
Import Service |
X |
|
|
Indexer Service |
X |
|
|
Inventory Service |
X |
|
|
Menu Service |
X |
|
|
Notification Service |
X |
|
|
Offer (Promotion) Service |
X |
|
|
Order Service |
X |
|
|
Payment Transaction Service |
X |
|
|
Pricing Service |
X |
|
|
Ratings Service |
X |
|
|
Sandbox Service |
X |
|
|
Scheduled Job Service |
X* |
X |
|
Search Service |
X |
|
|
Shipping Service |
X* |
X |
|
Tenant Service |
X |
|
|
Vendor Service |
X |
Note that rows with an X in both columns indicate that we feel that either topology is appropriate. The choice will depend on whether latency and performance are more important than the potential loss of data for your needs. X* indicates our recommended topology for that service.
Broadleaf Commerce allows you to bundle services into what we call FlexPackages. Services can be deployed and scaled granularly (individually). But this requires more hardware than is often needed. In these cases, we recommend FlexPackage bundling. Our default recommended approach is to deploy all services into the following balanced FlexPackages:
- Authentication - Authentication Services
- Browse - Catalog, Content, Menu, Offer, Pricing, Search, etc.
- Cart - Cart, Customer, Order, Payment, Inventory, etc.
- Processing - Import, Search Indexer, Scheduled Jobs, etc.
- Supporting - Admin Navigation, Admin User, Admin Metadata, Sandbox, Tenant, Notification, etc.
Note that FlexPackages maintain strictly bounded contexts so developers are not tempted to make direct internal calls between services which can lead to unwanted dependencies and unmanageable code. FlexPackages also allow you to configure each data source separately so that each service within a FlexPackage can have its own database (or database schema).
The following diagram depicts balanced FlexPackages deployed in US East and US West Regions. You’ll notice that there is a single SYNCHRONOUS topology that is deployed across US East, US Central, and US West. And you’ll also see that there are two XCLUSTERs deployed, each in US East and US West, with asynchronous replication.
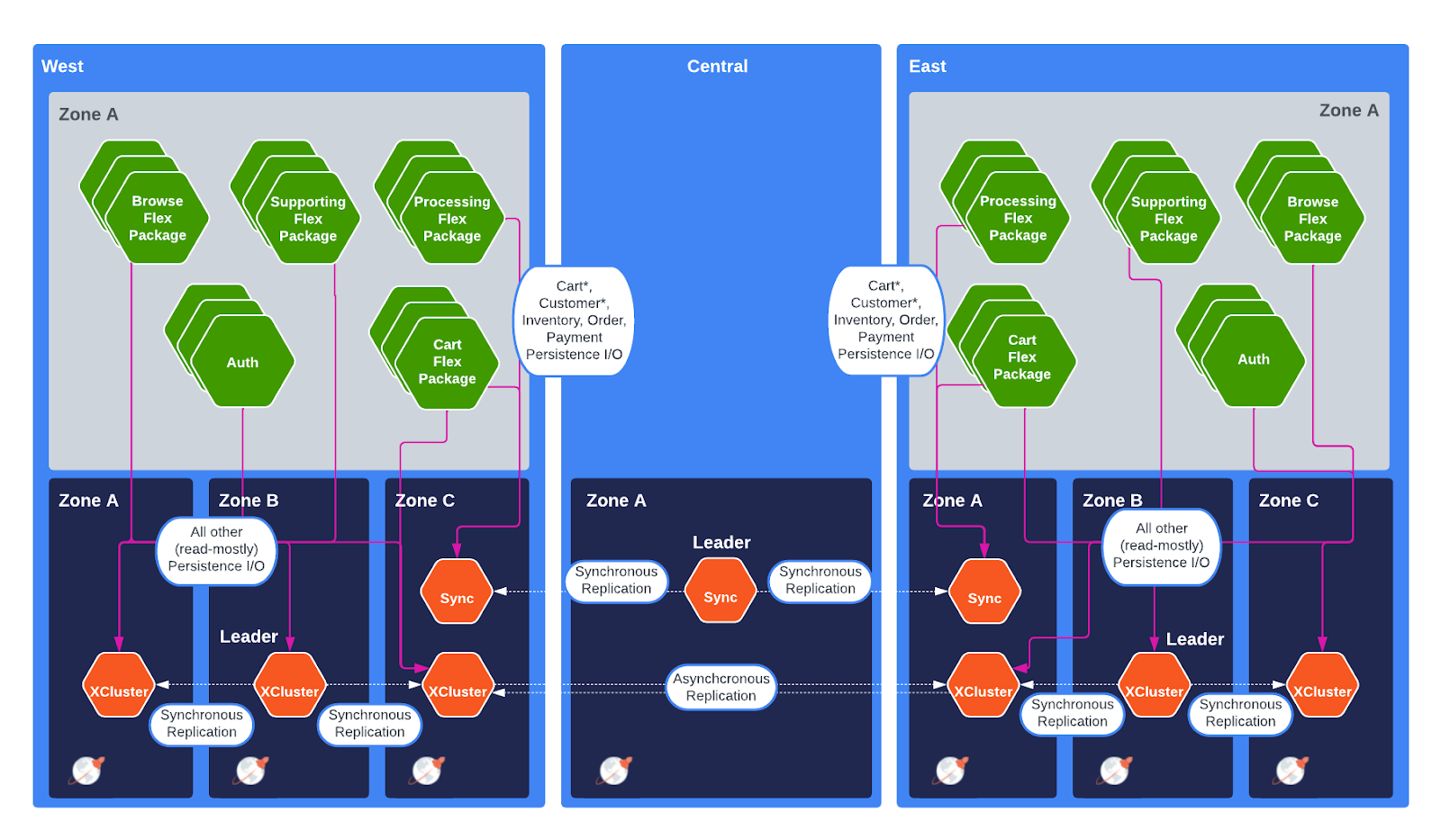
This diagram depicts nine database nodes. This is the bare minimum required for this architecture. Each node in our POC had four vCPU.
Additional Observations
Primary Key Generation
Broadleaf Commerce uses ULIDs for primary keys. As a result, no centralized or database-managed ID or sequence generator is required. ULIDs are similar to UUID - they are 128-bit, alpha-numeric strings that are algorithmically generated. However, they are sortable to millisecond precision. The first 48 bits are based on a millisecond precision timestamp. This is what makes them lexicographically sortable. The second 80 bits are entropy or randomness. It is statistically very improbable that you will have a collision with ULIDs, even when generating millions of ULIDs per second.
DDL and Liquibase Scripts
We observed that running DDL from Liquibase was slow, especially in a SYNCHRONOUS topology. It took somewhere between 20-30 minutes to execute all Liquibase scripts to build all schemas for all services. We found that batching change sets rather than running them one by one was much faster.
Another thing to note about DDL is that, at the time of writing, YugabyteDB does not replicate DDL between XCLUSTERs. This makes things more challenging for deploying DB changes to XCLUSTER because you have to deploy all changes individually to each side of the XCLUSTER and then turn on synchronization for new tables and then run DML to insert, update, or delete data as needed. So for XCLUSTER topologies, it’s best to run DDL to each side of the XCLUSTER, and then separately run DML to only one side of the XCLUSTER (which will replicate to the other side). The Yugabyte team assured us that they are working to address this so that it is transparent.
Security
YugabyteDB supports all of the role and permission-based security that you would expect from a database. It also allows encryption of data at rest and Transport Layer Security (TLS) for encryption over the wire. TLS can be turned on between the client (JDBC driver) and the servers and between clustered servers.
Load Balancing
YugabyteDB provides a proprietary JDBC driver that we employed. Technically, you can use a standard PostgreSQL driver and it works just fine. However, the YugabyteDB driver provides load-balancing capabilities. You simply specify some additional parameters in the JDBC connection URL: jdbc:yugabytedb://${host1},${host2}:5433/broadleaf?load-balance=true&topology-keys=gcp.us-east1.us-east1-a,gcp.us-east1.us-east1-b,gcp.us-east1.us-east1-c.
In this string, you’ll notice a comma-separated list of hosts. The initial connection will be made to one of these hosts. Then you’ll notice load-balance=true followed by topology-keys. This tells the driver to load balance, and the topology keys are used to help the driver discover which regions or availability zones you want to load balance across without needing to know the addresses of all of the nodes in each region or zone. The host you connect to first will inform the driver about other servers and in which zone and region they are located. The driver will then create new connections in a round-robin fashion from these details.
Unrelated to the JDBC driver, it’s important to note that the application can be load-balanced between either active region (e.g., US East and US West in our example). However, we recommend that for the duration of the user’s session, or until they experience a region failure, they should continue to be routed to the same region. This is to avoid toggling between regions, which can cause stale reads due to the fact that asynchronous replication can take several seconds or more. So whether you round-robin or use geo-location or another method to load balance between active regions, we recommend that the user’s “session” maintains an affinity for that region unless there is an outage or until they close their browser or end their session.
XCLUSTER “catch up”
One thing to be aware of with XCLUSTER is that if there is a region outage, bidirectional replication will cease during that outage. By default Yugabyte only keeps 15 minutes of transaction logs for XCLUSTER replication. You can change this configuration. However, Yugabyte cautions that the longer an outage, the longer it can take for replication to catch up when the outage ends. Your options, at this point, are to configure a much longer time to maintain transaction logs; or to do a manual restoration of your XCLUSTER that was down for an extended period of time.
This is why we recommend using a SYNCHRONOUS topology as much as possible for customer-related transactional data such as Customer, Cart, Order (post checkout), Inventory, and Payment Transaction records. This limits the impact on customers, systems, and processes that need to continue operating as normal and access the most recent transactional data (e.g., inventory or recently submitted orders), especially in a regional outage.
Cost
Not every company will need this level of availability and durability. There will be a premium in terms of hardware, license costs, and operational complexity for those that do. By definition, each YugabyteDB cluster requires a minimum of 3 servers to provide the ability for at least one server to fail without losing data. We have identified 3 clusters here:
- SYNCHRONOUS (a minimum of 1 node each in US East, US Central, and US West regions, for example)
- XCLUSTER East (a minimum of 3 nodes in the US East region)
- XCLUSTER West (a minimum of 3 nodes in the US West region)
The minimum number of nodes to achieve the architecture described above is nine nodes. We found that each node should have at least four vCPU. We found smaller nodes (2vCPU) were sluggish and even ran out of memory. Servers sized with at least four vCPU performed reasonably well for our POC. As a result, in order to achieve this architecture, you’ll need a minimum of 36 vCPU. YugabuteDB can scale vertically and horizontally. Yugabyte charges yearly license fees based on the number of vCPU. So, in addition to the duplicated application infrastructure in the US East and US West regions, for example, you’ll need to consider the additional hardware and license fees for the data tier.
Summary
Broadleaf Commerce provides a flexible, extensible, customizable, and scalable microservices-oriented eCommerce framework. When Broadleaf is deployed with YugabyteDB, you can achieve a true “Always On” geographically distributed, multi-master eCommerce environment that achieves or approaches five nines of availability.
This approach is very effective for companies that require this level of redundancy, resiliency, and scalability. Broadleaf is excited to partner with Yugabyte to accomplish this level of availability for our mutual customers.
